Article • 2 min read
Introducing the new Zendesk: Built for better customer relationships
Mikkel Svane


When we started Zendesk almost 10 years ago, our goal was pretty simple: Bring a sense of calm to the chaotic world of customer service. We’ve come a long way working alongside customers like you.
But we think we can do a lot more together.
For too long, business software has been one-sided: Built for the business at the expense of customers. It was designed around corporate departments, not customer experiences. Customers expect a single experience and conversation with companies, and that requires software designed for both sides of the relationship.
Today, we’re launching the new Zendesk, built for better customer relationships.
A product family
Zendesk has evolved from a single customer service product to a new, unified family of products focused on improving customer relationships. Our product family helps organizations understand their customers, improve communication, and offer support where and when it’s needed most.
We’ve created a common user interface across all of the products, making it easy to move among them and add new ones along the way. Toggling among products is as simple as visiting the product tray in the upper right corner.
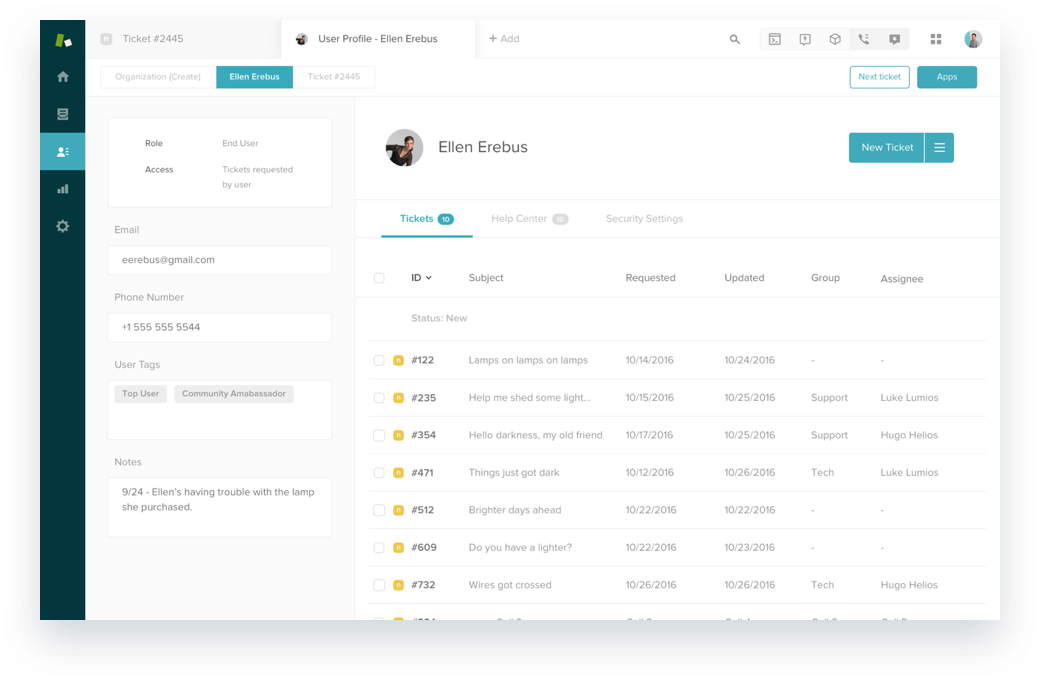
While the design is new, your account and pricing plan all stay the same. There’s nothing you need to do to keep using your Zendesk products.
A new brand identity
Zendesk is no longer both a company and a single product, so we needed to rethink our brand as well. We’ve created unique identities for each of our seven products, drawing our inspiration from the use of simple, everyday shapes. Each product identity shows the interaction of shapes—symbols of the relationship between a customer and business. For example, two rectangular blocks supporting one another represent the core Zendesk Support product.

All of the product identities fit together into the greater whole, which is represented by our new corporate logomark—a large Z comprised of the shapes connecting together.

A deeper understanding of relationships
We launched early access to Zendesk Explore and Zendesk Connect: two new products that together help you build a more personal connection with customers through analytics and customer intelligence.
Explore is our new analytics engine across Zendesk products and third-party customer data. Connect turns customer intelligence into proactive engagement and support so you can reach out to customers at the right time with the right information.
We hope you’ll explore the new Zendesk. You can learn more in our What’s New section, where you can also sign up for a webinar detailing the updates, and see our new brand in action in this video overview.



